Apache spark vs Apache Beam — What to choose & when ?

Introduction: The Need for Big Data Frameworks
In today’s world where terabytes or petabytes of data is been generated everyday, processing and deriving insights from massive datasets have become a critical necessity for businesses and researchers alike, driving innovation, informed decision-making, and unlocking unparalleled opportunities for growth and discovery. Big data frameworks serve as essential tools to address the challenges posed by the scale, velocity, and variety of data.
Why Big Data Frameworks?
Common programming languages and libraries struggle to handle the sheer volume of data. Traditional approaches fall short when dealing with complex data transformations, parallel processing, fault tolerance, and scalability. Big data frameworks alleviate these issues by providing specialized abstractions and tools tailored for large-scale data manipulation and analysis.
Introducing Apache Spark and Apache Beam:
Among the array of big data frameworks, Apache Spark and Apache Beam have emerged as prominent players. Apache Spark offers in-memory processing, enabling lightning-fast analytics and machine learning, while Apache Beam’s model-agnostic nature supports both batch and stream processing seamlessly. In this article, we delve into the intricacies of these frameworks, comparing their features, use cases, and integration potential. By understanding the unique advantages of Apache Spark and Apache Beam, readers can make informed decisions about which framework aligns best with their data processing needs.
Understanding Apache Spark :
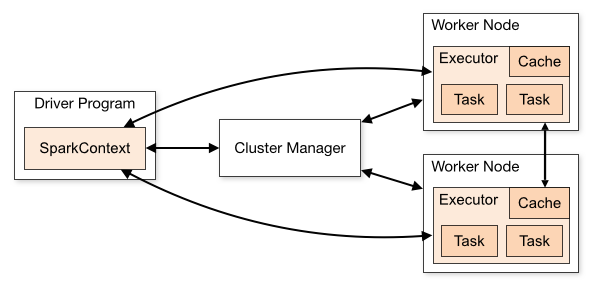
Apache Spark’s architecture, encompasses the RDD data structure and the DAG execution model, is the foundation of its exceptional capabilities. This architecture empowers Spark to process large datasets efficiently, handle failures gracefully, and harness in-memory computation. Through the integration of RDDs and the DAG execution model, Spark provides a robust framework for a wide range of data processing tasks.
Master-Slave Model and DAG Execution:
Spark operates on a master-slave model, where a central driver program orchestrates tasks across worker nodes in a cluster. Underlying this model is the DAG execution engine, which organizes tasks into a directed acyclic graph. This graph represents the sequence of transformations applied to RDDs and optimizes their execution for efficiency.
Resilient Distributed Dataset (RDD):
The RDD serves as the core data structure in Spark’s architecture. RDDs are fault-tolerant, partitioned collections of data that allow parallel processing across nodes. Consider a scenario where you’re analyzing customer behavior data. Spark’s architecture, driven by RDDs, enables the data to be divided into partitions and processed concurrently across worker nodes, delivering rapid insights.
Fault Tolerance and Lineage with DAG:
Imagine processing a large dataset and encountering a node failure. The DAG execution model ensures fault tolerance through RDD lineage. If a partition of data is lost due to a node failure, Spark can trace the lineage of transformations back to the original data source and recompute the lost partition, guaranteeing data integrity without unnecessary data replication.
In-Memory Computation and DAG:
For tasks like iterative machine learning algorithms, in-memory processing is crucial. The DAG execution model optimizes such iterative computations by caching intermediate results in memory. This caching, facilitated by RDDs and the DAG, accelerates algorithm convergence and reduces overall computation time.
Parallel Processing and DAG:
Spark’s architecture, guided by the DAG execution model, enables parallel processing. When analyzing a vast image dataset, for instance, the DAG scheduler divides the image processing tasks into a directed acyclic graph. This division allows multiple tasks to be processed concurrently on different nodes, leveraging the cluster’s parallel computing capabilities.
3. Understanding Apache Beam’s Architecture:
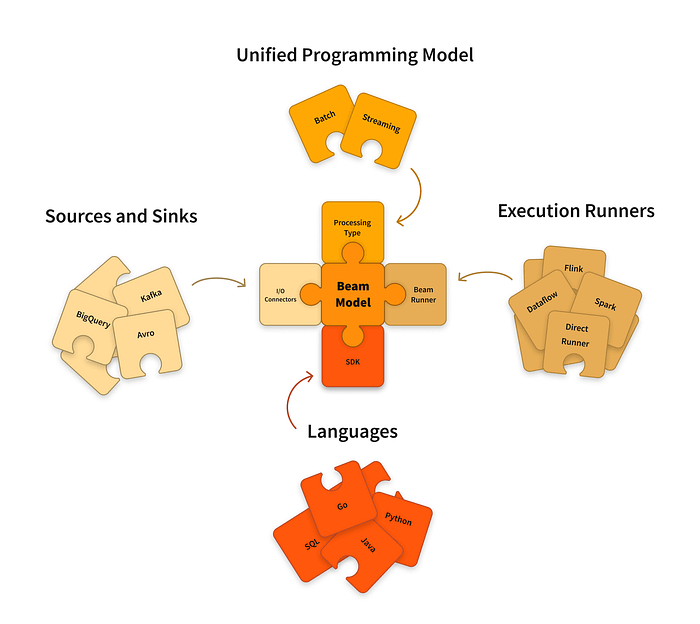
Apache Beam’s architecture, driven by the concept of data pipelines and the unified programming model, offers a versatile and adaptable framework for both batch and stream processing tasks. This architecture enables developers to build data processing pipelines that are consistent, portable, and capable of handling diverse data processing scenarios. Through the integration of data pipelines and the PCollection abstraction, Apache Beam provides a powerful toolset for transforming and analyzing data with ease.
Unified Data Processing Model: Apache Beam’s architecture revolves around a unified programming model that can handle both batch and stream processing tasks. This model allows developers to write data processing logic once and execute it consistently across different processing modes. Imagine processing user activity data, where the same logic can be used to analyze historical data in batch mode or process real-time events in stream mode.
Data Pipelines and PCollection:
Central to Apache Beam’s architecture is the concept of a data pipeline, represented by a series of transformations applied to data. The data is structured as a PCollection (PCollection, short for “Processing Collection,” is a key abstraction that encapsulates data in a distributed and parallelizable format within the data pipeline), which encapsulates the input and output data for each transformation. Consider a scenario where you’re analyzing sales data. Apache Beam’s architecture facilitates transforming the raw sales data into a structured format, performing calculations, and generating meaningful reports — all within a coherent pipeline.
Batch Processing with Data Pipelines:
Suppose you have a dataset of customer orders spanning a year. With Apache Beam’s architecture, you can construct a data pipeline to process and aggregate this data in batch mode. The pipeline reads the raw order data, applies transformations to calculate total sales per product, and generates a report summarizing the yearly sales.
Stream Processing with Data Pipelines:
Now, consider the same customer orders dataset, but you want to monitor real-time sales trends. Apache Beam’s architecture allows you to adapt the same data pipeline for stream processing. The pipeline processes incoming orders as they occur, continuously updating sales metrics and providing instantaneous insights.
Portability and Execution:
Apache Beam’s architecture promotes portability across different data processing backends, such as Apache Spark, Apache Flink, and Google Cloud Dataflow. This means that the same pipeline logic can be executed on various processing engines without requiring code changes. This versatility ensures that your data processing solution is not tied to a specific technology stack.
Key Feature Comparison :
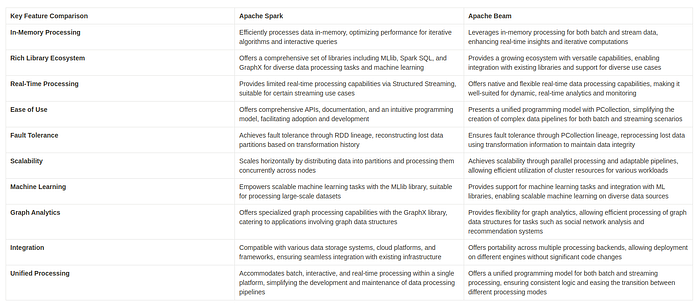
Here are some example scenarios comparing the framework’s preferences :
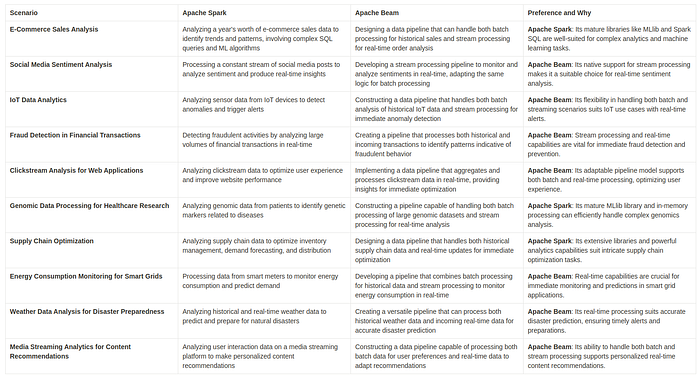
In conclusion, Apache Spark and Apache Beam offer diverse strengths for varied scenarios, empowering efficient and flexible data processing.
If you Like this post and wish to read more such content in future then join Data Engineering Daily group on Linkedin.
