Data lake Table formats : Apache Iceberg vs Apache Hudi vs Delta lake

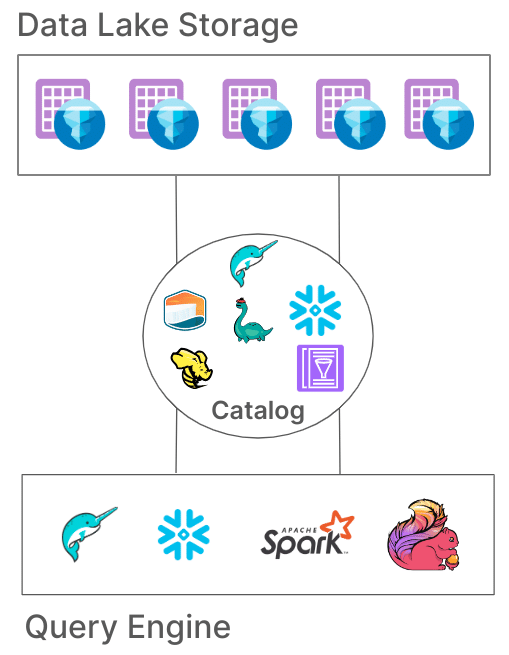
What is a Datalake?
Imagine a datalake as a massive container, capable of holding structured, semi-structured, and unstructured data from numerous sources, without the need for predefined schemas or strict data transformations. A datalake, in its simplest form, is a centralized repository that allows you to store a wide variety of data in its raw format. Think of it as a digital reservoir where you can pour in data from different sources, such as databases, applications, sensors, and more, without worrying about how it’s structured or organized. This flexibility is particularly valuable in today’s data-rich landscape, as it enables organizations to capture and retain data without upfront constraints.
What is a Table Format?
Now, imagine taking the contents of this datalake and arranging them into a neat and organized format, much like a table in a database. A table format, in the context of a datalake, brings structure to the chaos. It defines how data is organized, stored, and accessed within the datalake. Think of it as a way to create logical compartments within the vast datalake, making it easier to manage, query, and analyze the data.
Why are Datalakes and Data Lake Table Formats Necessary?
Data lakes and their associated table formats have become a necessity due to the explosive growth of data. Traditional databases and storage solutions struggle to keep up with the sheer volume, variety, and velocity of data being generated. Datalakes provide a scalable solution for storing this data without upfront constraints on its structure. However, to make sense of the data and derive meaningful insights, organization is key. This is where data lake table formats step in. They enable efficient data management, facilitate faster querying, and allow for the evolution of data schemas over time. In essence, data lake table formats bridge the gap between the raw power of a datalake and the structured organization needed for effective analysis, making them an essential component of modern data architectures.
Key Features Comparison of these Table Formats

What the heck is Time Travel anyway ?
Time travel, within the context of data lake table formats, refers to the ability to query data as it existed at a specific point in time. This feature has transformative implications for retrospective analysis, auditing, and compliance. Imagine being able to peer into your data lake as it appeared weeks, months, or even years ago, enabling you to uncover trends, anomalies, and insights that might otherwise go unnoticed.
Data Versioning:
Data versioning complements time travel by providing a mechanism to capture and preserve different snapshots or iterations of your data over time. With data versioning, you can confidently make changes to your data without fear of irreversibly altering historical records. Each version becomes a distinct point in the data’s lifecycle, creating a historical trail that offers a comprehensive view of data changes.
Examples:
- Financial Analysis with Time Travel:
- Use Case: When using Delta Lake for storing transactional data. As auditors conduct a review, they need to analyze the state of the data as it appeared during specific quarters over the last two years. Delta Lake’s time travel feature enables auditors to query the data at precise time points, facilitating accurate financial assessments and compliance checks.
2. Evolving Product Catalog with Data Versioning:
- Use Case: When using Apache Iceberg to manage its product catalog. When adding new products or updating existing ones, the platform creates new versions of the catalog. This data versioning ensures that customers can see the product catalog exactly as it was at the time they made a purchase, maintaining data consistency for order fulfillment and customer satisfaction.
3. Clinical Research Analysis:
- Use Case: When using Apache Hudi, Researchers are conducting a study on the progression of a particular medical condition. By utilizing Apache Hudi’s data versioning capabilities, they can track changes to patient data over time, ensuring accurate analysis and longitudinal insights into the condition’s development.
4. Media Streaming Analytics:
- Use Case: A media streaming service like Netflix/ Disney+ /Amazon prime leverages Delta Lake to manage user engagement data. By employing time travel, the service’s data analysts can analyze user behavior trends during major events such as movie releases or sports events, offering insights into viewer preferences and optimizing content recommendations.
In each of these scenarios, the time travel and data versioning features of Apache Iceberg, Apache Hudi, and Delta Lake empower organizations to explore the past, assess changes, and gain a deeper understanding of their data’s historical context. These capabilities not only enhance analytical accuracy but also play a pivotal role in compliance, auditing, and strategic decision-making, reinforcing the value of these data lake table formats in today’s data-driven landscape.
Use Cases and Applications
As organizations navigate the dynamic landscape of data management, data lake table formats such as Apache Iceberg, Apache Hudi, and Delta Lake offer a range of use cases and applications that cater to diverse business needs. Let’s explore how these formats come into play across various scenarios, along with examples of companies leveraging each format:
1. Data Warehousing and Analytics:
— Use Case: Storing and analyzing historical sales data for business insights.
— Example: We can use Apache Iceberg to manage vast amounts of sales data spanning several years. The format’s schema evolution and time travel features enable them to seamlessly add new data sources and analyze sales trends over different periods.
2. Real-time Data Processing:
— Use Case: Processing real-time financial transactions for fraud detection.
— Example: A fintech startup employs Apache Hudi to process incoming financial transactions in real time. The format’s support for near-real-time updates ensures that the latest transaction data is continuously processed, enhancing their fraud detection algorithms.
3. Data Integration and ETL:
— Use Case: Integrating data from various departments into a unified analytics platform.
— Example: A healthcare organization adopts Delta Lake to consolidate patient data from different hospital departments. The format’s ACID transactions and schema evolution capabilities streamline data integration and transformation, ensuring accurate reporting.
4. Advanced Analytics and Machine Learning:
— Use Case: Developing personalized recommendation systems for an e-commerce platform.
— Example: An e-commerce platform like Amazon/flipkart can use Apache Iceberg to store user behavior data. The format’s time travel feature allows data scientists to analyze past user interactions and develop more accurate recommendation algorithms.
5. Data Archiving and Compliance:
— Use Case: Archiving financial records for regulatory compliance.
— Example: A financial institution relies on Delta Lake to archive and retain financial transaction records. The format’s time travel and versioning capabilities ensure that historical data remains immutable and auditable, meeting compliance requirements.
6. IoT Data Management:
— Use Case: Monitoring and optimizing energy consumption in smart buildings.
— Example: An energy management company uses Apache Hudi to process data from IoT sensors in real time. The format’s support for streaming data allows them to analyze energy consumption patterns and make informed decisions to optimize efficiency.
7. Log and Event Data Analysis:
— Use Case: Analyzing server logs for performance optimization.
— Example: We can use Delta Lake to store and analyze server logs. The format’s ACID transactions and query optimization capabilities enable efficient log analysis, helping them identify and address performance bottlenecks.
8. Collaborative Data Sharing:
— Use Case: Sharing customer data with strategic partners.
— Example: An e-commerce platform like Amazon/Flipkart can use Apache Iceberg to securely share customer demographic data with its marketing partners. The format’s data retention policies and access controls ensure that data is shared in a controlled and compliant manner.
In each of these use cases, the chosen data lake table format plays a crucial role in enabling efficient data management, analysis, and collaboration. These real-world examples showcase how Apache Iceberg, Apache Hudi, and Delta Lake can be tailored to specific business needs, underlining their versatility and impact across diverse industries and applications.
References :
1. https://www.dremio.com/blog/comparison-of-data-lake-table-formats-apache-iceberg-apache-hudi-and-delta-lake/
3. https://iomete.com/blog/apache-iceberg-delta-lake
4. https://lakefs.io/blog/hudi-iceberg-and-delta-lake-data-lake-table-formats-compared/



![Building an Analytics Solution for Ad campaigns -[Part 1 -Data Modelling]](https://miro.medium.com/v2/resize:fit:679/1*4gabpQzxCE2xult1bIn5dg.png)